waizui
Let’s build a GPT-2 (III)
In part II, I explained how the attention mechanism works. This time, let’s continue to train a language model.
The Implementation
To build a fully functional GPT2, we need to add residual connections ,feed-forward layer and LayerNorms.
I will skip the detailed explanation, since these are common in other deep learning architectures.
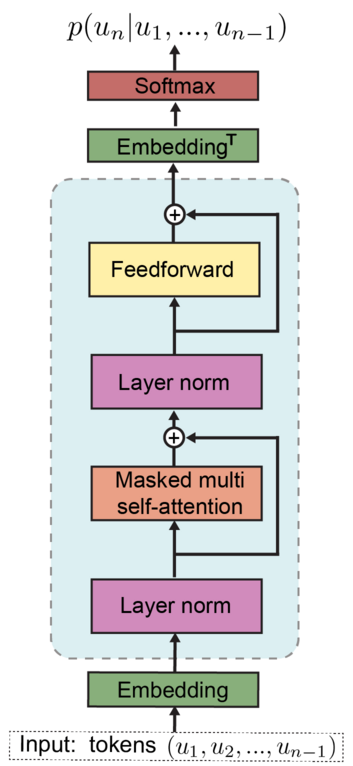
Here is an implementation of GPT2 shown in the picture:
class GPTModel(nn.Module):
def __init__(self, cfg: GPTConfig) -> None:
super().__init__()
self.emb = GPTEmbedding(
cfg.context_len, cfg.vocab_size, cfg.emb_dim, cfg.drop_rate
)
self.trf_blocks = nn.Sequential(
*[TransformerBlock(cfg) for _ in range(cfg.n_layers)]
)
self.final_norm = LayerNorm(cfg.emb_dim)
self.out_head = nn.Linear(cfg.emb_dim, cfg.vocab_size, bias=False)
def forward(self, in_idx: Tensor):
x = self.emb(in_idx)
x = self.trf_blocks(x)
x = self.final_norm(x)
# this implementation uses a separate output head,
# GPT models use token embedding weights(weight tying)
logits = self.out_head(x)
return logits
Here is the transformer block.
class TransformerBlock(nn.Module):
def __init__(self, cfg: GPTConfig) -> None:
super().__init__()
self.att = MultiHeadAttention(
cfg.emb_dim, # input dimension
cfg.emb_dim, # output dimension
cfg.context_len,
cfg.drop_rate,
cfg.n_heads, # number of attention heads
cfg.qkv_bias, # boolean, whether to use bias for Q,K,V layers
)
self.ff = FeedForward(cfg)
self.norm1 = LayerNorm(cfg.emb_dim)
self.norm2 = LayerNorm(cfg.emb_dim)
self.drop_shortcut = nn.Dropout(cfg.drop_rate)
def forward(self, x):
shortcut = x # store original input
# pre-layernorm(norm before attention), get better training result
x = self.norm1(x)
x = self.att(x)
x = self.drop_shortcut(x)
x = x + shortcut # add original input back
shortcut = x
x = self.norm2(x)
x = self.ff(x)
x = self.drop_shortcut(x)
x = x + shortcut
return x
Training
Basically, what a language model does is generate the next token based on given input tokens.
So, training a GPT2 model means maximizing the following likelihood:
\[L_1(U)= \sum_i \log P(u_i \mid u_{i-k}, \ldots, u_{i-1}; \Theta)\]where $U=\lbrace u_1,\dots,u_n \rbrace$ is an unsupervised corpus of tokens, $\Theta$ is a neural network that predicts $u_i$, $k$ is context length.
To be as simple as possible, let’s take $k = 2, n=4$ and $U =\lbrace u_1 = I, u_2 = love, u_3 = eat, u_4 = apple \rbrace$ as an example.
If input is I love, we need to maximize the probability of next-token-is-eat, which is $P(eat|I,love)$.
If input is love eat, we need to maximize the probability of next-token-is-apple, which is $P(apple|love,eat)$. (inputs have context length of 2)
In PyTorch, we use $-L_1$, so the objective becomes to minimize the cross-entropy loss.
def calc_loss_batch(
input_batch: Tensor, target_batch: Tensor, model: GPTModel, device: Device
):
input_batch = input_batch.to(device)
target_batch = target_batch.to(device)
logits = model(input_batch)
# logits : [b,num_tokens, vocab_size] -> [b*num_tokens, vocab_size]
# target : [b,num_tokens]->[b*num_tokens]
loss = nn.functional.cross_entropy(logits.flatten(0, 1), target_batch.flatten())
return loss
Take the I love eat apple example, the input_batch and target_batch in this code are [I, love] and [love, eat] respectively. If the corpus is longer,
we can split it into more chunks.
The core part of training loop is simple, it looks like this:
prepare data ...
for epoch in range(num_epochs):
model.train()
for input_batch, target_batch in train_loader:
optimizer.zero_grad()
loss = calc_loss_batch(input_batch, target_batch, model, device)
loss.backward()
optimizer.step()
evaluate model ...
Generate Text
After training, the GPT2 model can be used to generate text.
idx is an expanding id list, every time the model generates a new token id we put it into this list,
The context_size is a hard limit, if the length of idx exceeds context_size, model cannot see tokens before length - context_size.
We divide logits by temperature, adjusting the distribution probability of tokens. temperature>1 will make tokens distribution more even,
and temperature<1 will make distribution more concentrated, which means more confident about the generated results.
If we use high temperature, the output tends to be more creative, but sometimes it may cause incorrect grammar or nonsensical output. To address this, we use Top-k sampling to keep only the top-k highest-probability candidate tokens.
def gen_text(
model: GPTModel,
idx: Tensor, # [1, num_tokens]
max_new_tokens,
context_size,
temperature=0.0,
top_k=None,
eos_id=None,
):
for _ in range(max_new_tokens):
idx_cond = idx[:, -context_size:]
with torch.no_grad():
logits: Tensor = model(idx_cond)
logits = logits[:, -1, :]
if top_k is not None:
top_k_logits, _ = torch.topk(logits, top_k)
min_val = top_k_logits[:, -1]
# remember the property of softmax we mentioned in part II?
logits = torch.where(
logits < min_val, torch.tensor(float("-inf")).to(logits.device), logits
)
if temperature > 0.0:
logits = logits / temperature
probs = torch.softmax(logits, dim=-1)
idx_next = torch.multinomial(probs, num_samples=1)
else:
idx_next = torch.argmax(logits, dim=-1, keepdim=True)
# break if encounter end of sequence id
if idx_next == eos_id:
break
idx = torch.cat((idx, idx_next), dim=1)
return idx
Finally, we can use tokenizer to convert these generated token ids to text:
def text_to_token_ids(text, tokenizer: Tokenizer) -> Tensor:
return torch.tensor(tokenizer.encode(text)).unsqueeze(0)
def token_ids_to_text(ids: Tensor, tokenizer: Tokenizer) -> str:
return tokenizer.decode(ids.squeeze(0).tolist())
def gen_and_print(
model: GPTModel, tokenizer: Tokenizer, device: Device, start_context: str
):
context_size = model.emb.pos_emb.weight.shape[0]
encoded = text_to_token_ids(start_conetxt, tokenizer).to(device)
with torch.no_grad():
token_ids = gen_text(
model, encoded, 50, context_size, temperature=1.0, top_k=25
)
text = token_ids_to_text(token_ids, tokenizer)
print(text.replace("\n", " "))
Instruction Fine Tuning
To be continued …